在前面的文章裡,我們聊了 NLP 是什麼、語料的前處理,也看過文字要怎麼轉換成數字。但是,這些都只是前置預備作業!
真正要讓電腦能夠做各種 NLP 任務的關鍵其實是 「模型訓練」!!
「模型訓練」可以想成是電腦學習的過程。我們把資料餵給模型,讓它去學習資料中規律,最後可以依照他所學去做出判斷。(像以下這張梗圖XD)

圖片來源:https://x.com/bindureddy/status/1356787511469641729
這過程也有點像是學生要學習跟考試:
所以就像一開始什麼都不會的學生,透過一些練習和回饋,慢慢掌握題目的模式,目的是在最後遇到沒看過的考題也能答出來。對 NLP 而言,模型訓練的目的就是把「資料中的規律」轉化成「模型能理解並應用的能力」。
接下來我們來了解實際的訓練流程跟一些重要的概念~
先收集我們需要的語料,例如:電影評論、餐廳評論、PTT文章等等。
然後再清理語料:去掉多餘的符號、重複的文字(Regex 應用)
也會對語料進行一些前處理:斷詞、詞性標註
有些任務需要有標準答案,所以會需要做一些語料標註。例如: 想判斷電影評論為好評 or 負評,我們需要標註出我們搜集的訓練資料是好評還是負評。
其中一個方法是將文字向量化。因為電腦不懂文字,它只懂數字,所以我們要把文字轉成模型能理解的形式:
我們也可以加上一些 語言學特徵,例如:
比方說,在做情感分析時,如果評論裡充滿「超好吃」、「必點」,那大概就是好評,如果是提到「難吃」、「不推」,就比較偏負評。所以除了文本的向量,加上更多的語言特徵,有時候能讓模型更容易捕捉語言中的細微差別~
不同的模型適合做不同的任務,依據任務的需求,像是資料量多寡、任務簡單還是複雜、你想要結果容易解釋還是追求準確率等等的考量,可以選擇適合的模型。
模型拿到資料後,會進行資料劃分,將資料分成三份或兩份:
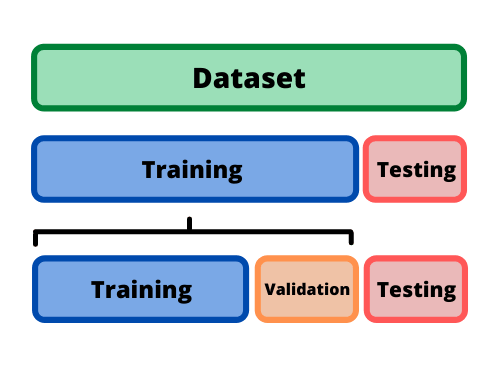
圖片來源:https://datamastersclub.com/how-to-train-and-test-data-like-a-pro/
訓練集就像平常練習用的題目,驗證集是用來調整學習方式的模擬考,而測試集才是真正的期末考,來檢驗模型在完全新的情境下的實力。所以通常訓練集會是最多的,驗證集跟測試集會比較少。
當模型用訓練集學完之後,接下來會用驗證集和測試集來看看它在沒見過的新資料上表現得怎麼樣。那要怎麼打分數呢?這時候就會用到底下這個 「混淆矩陣」(Confusion Matrix)。
混淆矩陣會把「真實標籤」和「模型預測標籤」的結果交叉排列,分成「正/負」的組合。透過這張矩陣,我們就能清楚看到模型在哪些地方判斷正確、在哪些地方出錯,進而計算出各種不同的評估指標。
可以想成模型有沒有誤認壞人為好人。
可以想成模型有沒有把好評通通撈回來。
總之,模型訓練就像是電腦的學習歷程。今天我們聊的只是最基礎的概念,實際上模型訓練還可以分成許多不同的類型,例如「監督式學習」、「非監督式學習」和「半監督式學習」等等。如果大家有興趣,可以再深入去了解這些不同的學習方式~
不過有了這一層基礎理解之後,接下來我們就能進一步往下走,探索各種具體的模型方法啦!在下一篇,我們會先從最經典的機器學習模型 Naive Bayes 開始,看看它是怎麼用簡單的機率規則,完成文本分類任務吧!

